GraphQL Optimization - Lookaheads - Prefetching
This post is a part of the series about optimizations in GraphQL servers. This post requires a basic understanding of GraphQL — especially the resolvers. If you’ve not read my previous posts in this series, I recommend you to read them.
In the previous posts, we dealt with a few of the complexities involved in optimizing data between a GraphQL server and a backend server (data provider). In this post, I’ll explain another advantage of lookahead — prefetching.
What are LookAheads?
As a recap from previous posts, LookAheads are a concept of knowing what the next action is in the context of the current action. In GraphQL context, when resolving a field foo, a lookahead can be getting the sub-fields of foo. We can take advantage of the fact that we know the sub-fields ahead of time — before the sub-fields own resolution in the execution pipeline.
Sequential fetch
Let’s start with an example as usual —
query {
product(id: "foo") {
name
inWishlist
}
}
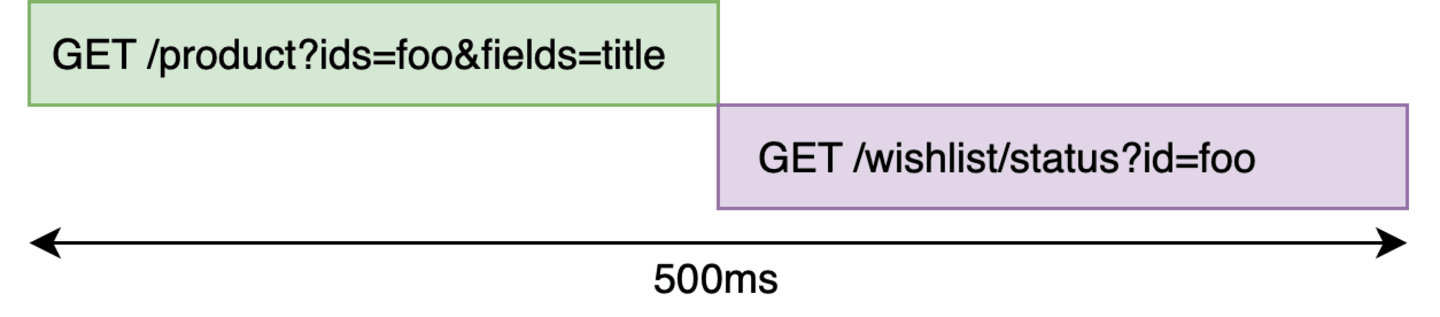
Here, we see 2 fields — name and inWishlist. Let’s assume that the name comes from the product backend and the field inWishlist is a Boolean and the value is available from the wishlist backend. Also, let’s say, to check if the product is in wishlist, we need to check that the customer is logged in and has a valid token to access the wishlist.
It’s common to construct the inWishlist as a separate resolver —
resolvers.Query.product = () => {
// ... get product from product backend
};
resolvers.Product.inWishlist = async (parent, _, context) => {
await fetch(`/auth/isValidToken`, context.req.headers);
return fetch(`/wishlist/status?${parent.id}`);
};
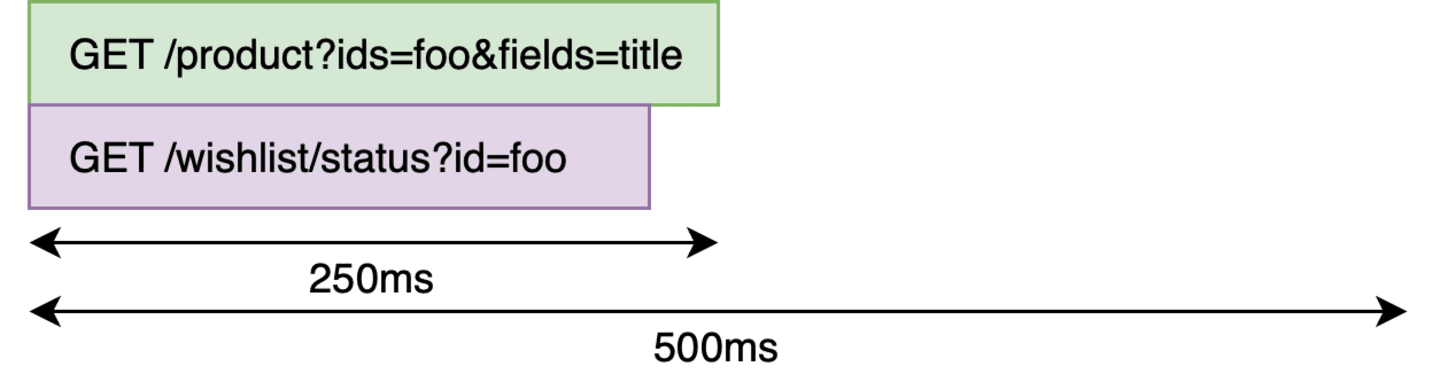
The only problem in this implementation is that these two requests are sequential. But the wishlist call does not depend on anything from the product backend. So why can’t those two requests fire in parallel?
Promise.all
In relatively small projects, it’s relatively easy to solve it by handling them using a construct like Promise.all —
resolvers.Query.product = async (_, { id }, context, info) => {
const [product, inWishlist] = await Promise.all([
fetch(`/product...`),
fetch(`/auth/isValidToken`).then(() => fetch(`/wishlist/status`)),
]);
product.inWishlist = inWishlist;
return product;
};
But, we are missing some nuances — error handling. In a resilient system, we do not want errors of one affecting others unless necessary. What happens if the wishlist call fails? or what happens when the auth call fails? The failure of these calls affect the product and we throw an error for the entire product call. This is because of the way Promise.all works — the first rejection discards all other results and this rejection is returned as the result.
Failing to serve the product because the wishlist call failed might not be good for the users. One option is to provide it a default value and the other is to bake this into the Schema design where the field is nullable. I’d leave this topic for another post.
Promise.allSettled
Promise.allSettled is an API which will be available in the next version of JavaScript ES2020 and it will fit our use-case —
const [productResult, wishlistResult] = await Promise.allSettled([
fetch("/product..."),
fetch("/auth...").then(() => fetch("/wishlist")),
]);
let inWishlist = false;
if (wishlistResult.status === "fulfilled") {
inWishlist = wishlistResult.value;
}
if (productResult.status === "fulfilled") {
productResult.value.inWishlist = inWishlist;
return productResult.value;
} else {
throw productResult.reason;
}
As we can see, even for relatively small projects and simple use-cases, say, a couple of fields, there can be a lot of states to handle for each promise. When we look at the code that executed sequentially, it looks more intuitive. I want to take a step back and think about GraphQL — this is exactly what GraphQL already does for us through resolvers — each field in the same level is resolved concurrently and errors are handled and propagated based on nullability constrain declared in the schema. How can we leverage GraphQL semantics and execution to parallelize these two calls?
DataLoaders
For the next section, we are going to use DataLoaders - a way to batch multiple data requests into a single batched request. In the previous post, I have explained about DataLoaders and field filtering in a DataLoader.
const loader = new DataLoader(keys => getBatchedKeys(keys), {
batch: true,
cache: true,
);
DataLaoder is a batcher for data requests. Data is requested via a loader.load() function and each call is added to a batch and eventually dispatched. We are interested in the caching part. When cache is true, the loader caches the response.
Pre-fetching and caching
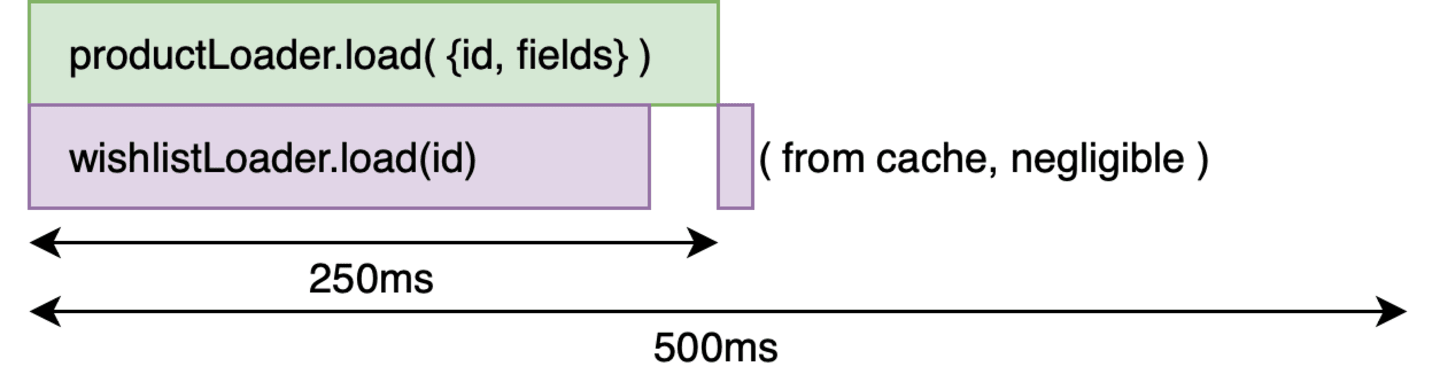
The strategy to our problem is to pre-fetch the resources and cache them. When the actual call goes through, we simply return the result from the cache. In the product resolver, we pre-fetch the wishlist resource through a dataloader just by firing the request and not waiting for it to complete.
Also, in previous example with Promise.allSettled, we see that the wishlist call will be fired even if the query did not include the field inWishlist. So let’s eliminate that unnecessary call — and as you might have guessed, we will use look-aheads to do that. Since we still use the separate inWishlist resolver, like we did in the first place, we still get the advantage of error handling.
So, in steps, we will do the following —
- Look-Ahead and get the sub-fields in product.
- Fire the product call. But do not wait for the call to be fulfilled.
- If the subfields include
inWishlist, fire the wishlist loader call. Discard the result. This is used for priming the cache. - Return the pending promise of the product call as the result.
In code, it will look like this —
resolvers.Query.product = (_, { id }, __, info) => {
const fields = getFields(info);
// fire the product call
// NOTE: There is no await
const productPromise = productLoader.load({ id, fields });
// fire the wishlist call if the lookahead result
// contains inWishlist
if (fields.includes("inWishlist")) {
// NOTE: There is no await and the result is simply discarded
// This simply primes the cache of the wishlist loader
wishlistLoader.load(id);
}
// and we return the product
return productPromise;
};
resolvers.Product.inWishlist = (parent) => {
// this will load from the cache
return wishlistLoader.load(parent.id);
};
Conclusion
LookAheads are a powerful concept that gives us a lot of opportunities to optimize GraphQL services. In the first post, we saw that they can be used to reduce the amount of data fetched. In this post, we saw that they can be used in pre-fetching to parallelize multiple independent calls to backend.
There are many many advantages of just knowing what’s going to happen next before it happens — by the process of looking ahead.
I hope you enjoyed reading these posts. If you have any questions or comments, please feel free to tweet to me @heisenbugger.